What the Stanford hallucination study actually revealed — and why the industry's response missed the point
Stanford found that premium legal AI tools hallucinate 17-33% of the time. But the most dangerous finding wasn't the hallucination rate — it was misgrounding.
By Auryth Team
The most dangerous AI error isn’t the one that’s obviously wrong. It’s the one that looks exactly right.
In May 2024, researchers from Stanford RegLab published the first preregistered empirical evaluation of commercial legal AI tools (Magesh et al., 2024). They tested Lexis+ AI, Ask Practical Law AI, and later Westlaw AI-Assisted Research across 202 legal queries, hand-scored by legal experts. The headline finding — hallucination rates of 17–33% — shocked the industry. But the finding that should have worried professionals most received far less attention.
What Stanford actually found
The numbers are stark:
| Tool | Accurate | Incomplete | Hallucinated |
|---|---|---|---|
| Lexis+ AI | 65% | 18% | 17% |
| Ask Practical Law AI | 19% | 62% | 17% |
| Westlaw AI-Assisted Research | 42% | 25% | 33% |
| GPT-4 (baseline, prior study) | — | — | 58–82% |
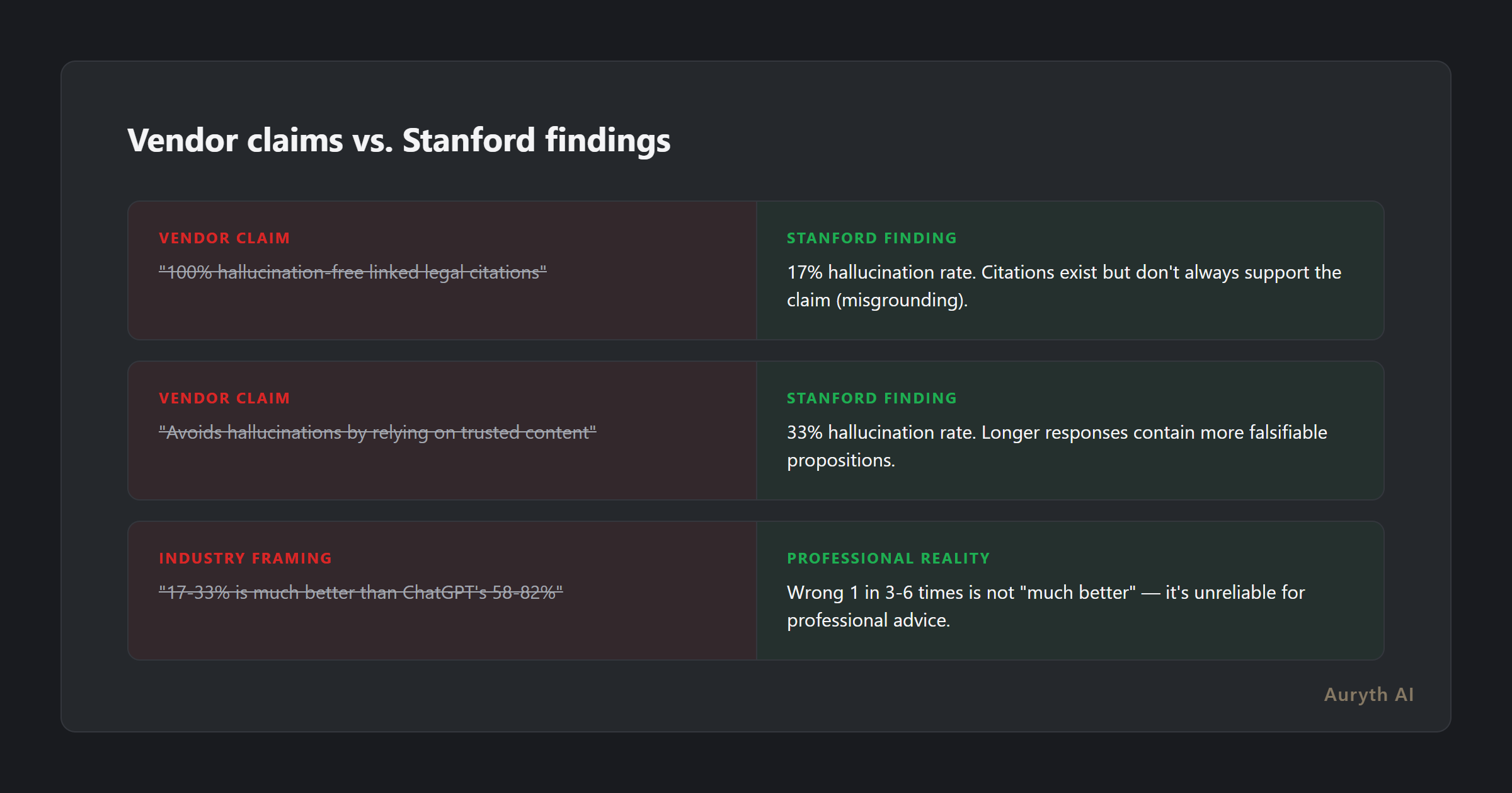
These are tools marketed at thousands of euros per month to professionals who rely on them for client advice. LexisNexis had claimed “100% hallucination-free linked legal citations.” Thomson Reuters claimed their tools “avoid hallucinations by relying on trusted content.”
The Stanford researchers’ conclusion was blunt: “Providers’ claims are overstated.”
Misgrounding: the finding everyone missed
The study introduced a taxonomy that separates hallucinations into distinct failure modes. The most important distinction: the difference between fabrication and misgrounding.
Fabrication is what most people think of when they hear “AI hallucination.” The AI invents a case that doesn’t exist — like in the Mata v. Avianca incident, where attorneys submitted a brief containing entirely fictional case citations generated by ChatGPT. This type of error is embarrassing but catchable. A quick database search reveals the case doesn’t exist.
Misgrounding is subtler and more dangerous. The AI describes the law correctly, cites a real case that actually exists, but the cited case doesn’t support the claim being made. The citation is valid. The legal statement sounds accurate. But the source doesn’t say what the AI says it says.
This passes superficial review. The citation checks out — the case is real. The legal proposition sounds right. A time-pressed professional who clicks through to the source might skim the headnote, see the right topic area, and move on. The misgrounding survives because it looks like good research.
The most dangerous citation is the one that exists but doesn’t say what you think it says.
The Stanford study documented specific failure modes: systems misunderstanding case holdings, confusing litigant arguments with court opinions, misrepresenting which courts control precedent, and attributing dissenting views to the majority.
The “better than ChatGPT” fallacy
The industry’s dominant response was predictable: “17–33% is dramatically better than ChatGPT’s 58–82%. RAG works.”
This framing is wrong for three reasons.
The baseline is meaningless. Comparing a premium professional tool to a free consumer chatbot is like comparing a commercial airline’s safety record to a bicycle’s. Nobody evaluates professional tools against consumer alternatives. The relevant question isn’t “is it better than ChatGPT?” but “is it reliable enough for professional practice?”
The bar is too low. Would you retain a junior associate who gets 1 in 3–6 answers wrong? Would you trust a tax advisor whose citations are misgrounded a third of the time? In medicine, a diagnostic tool with 17–33% error rates would never be marketed as “hallucination-free.” Professional standards demand higher reliability than “better than the worst alternative.”
The long-form amplification effect. Stanford found that Westlaw’s higher hallucination rate correlated with longer responses — averaging 350 words versus 219 for Lexis. More words mean more falsifiable propositions, which means more chances for error. Tools that generate longer, more detailed responses aren’t necessarily more helpful — they may simply be more likely to contain at least one hallucination that the user must catch.
What this means for Belgian tax professionals
Belgian tax law is precisely the domain where these failure modes are most dangerous. The Stanford study identified four categories of errors — jurisdiction confusion, authority hierarchy violations, temporal misapplication, and entity substitution. Every one of these maps directly onto Belgian tax practice.
Jurisdiction confusion. Belgian tax law operates across federal, Flemish, Walloon, and Brussels-Capital layers. The same economic activity may be governed by different tax regimes depending on the region. An AI tool that confuses federal WIB 92 provisions with Flemish VCF provisions — both of which discuss similar concepts with overlapping terminology — produces exactly the type of misgrounded output Stanford identified.
Authority hierarchy violations. A circular from FOD Financiën does not carry the same legal weight as an article of law or a ruling from the Hof van Cassatie. An AI tool that cites administrative guidance as if it were statutory authority commits an authority hierarchy violation that most professionals would miss on quick review.
Temporal misapplication. Belgian tax law changes frequently — programme laws amend dozens of provisions twice per year. An AI tool that retrieves a correct legal principle but from a superseded version of the law produces advice that was right last year but wrong today.
The OVB (Orde van Vlaamse Balies) has recognised these risks. Their AI guidelines explicitly state that lawyers retain “ultimate responsibility for every opinion, every pleading and every procedural document” and should work preferably with tools that provide “clear source references” enabling verification.
The verification paradox
Here lies the uncomfortable truth. If every AI-generated citation must be manually verified against the primary source — which the Stanford study suggests is necessary — what exactly is the time saving?
The tool generates citations faster than manual research. But verification takes the same time regardless of who found the citation. A professional still needs to read the source, confirm it supports the proposition, and check that it remains current. The net efficiency gain may be smaller than vendors claim — or even negative when you factor in the time spent processing longer AI-generated responses that contain more falsifiable propositions.
This doesn’t mean legal AI tools are useless. It means the value proposition is different from what’s being marketed. The value isn’t “do less verification.” It’s “search more broadly, verify what the tool surfaces, and catch connections you would have missed manually.”
What good looks like: transparency over perfection
The Stanford study doesn’t prove that legal AI is impossible. It proves that accuracy claims without published evaluation metrics are meaningless. “Hallucination-free” is a marketing claim, not a technical specification.
What professionals should demand instead:
Published accuracy metrics. If a vendor claims reliability, they should publish evaluation results — not on cherry-picked queries, but on systematic, preregistered benchmarks. If they won’t share their numbers, ask why.
Confidence indicators. A tool that tells you “I’m 85% confident in this answer” is more useful than one that presents every response with equal authority. Uncertainty quantification turns unreliable output into decision-support — because it tells the professional where to focus their verification effort.
Citation validation. Post-generation verification that checks whether cited sources actually support the claims being made. This is the direct countermeasure to misgrounding — and most tools don’t do it.
Common questions
Does the Stanford study mean legal AI tools are useless?
No. It means their accuracy is lower than vendors claimed, and that professional verification remains essential. The tools are valuable for broad search and initial research — but they are not substitutes for professional judgment, and marketing them as “hallucination-free” is misleading.
Why did Westlaw have a higher hallucination rate than Lexis?
The researchers attributed this partly to response length. Westlaw generates longer, more detailed responses — which contain more falsifiable propositions and therefore more opportunities for error. This is a tradeoff: more detail brings more utility but also more risk.
Has the Belgian bar or ITAA taken official positions on AI hallucination risk?
The OVB guidelines explicitly address AI use in legal practice, requiring that lawyers retain full responsibility for AI-assisted output and work with tools that provide verifiable source references. The ITAA deontological code similarly holds tax advisors responsible for the accuracy of their professional advice, regardless of the tools used to produce it.
Related articles
- AI hallucinations: why ChatGPT fabricates sources (and how to spot it) → /en/blog/ai-hallucinaties-fiscaal-en/
- Why transparency matters more than accuracy in legal AI → /en/blog/transparantie-vs-nauwkeurigheid-en/
- What is confidence scoring — and why it’s more honest than a confident answer → /en/blog/confidence-scoring-uitgelegd-en/
How Auryth TX applies this
Auryth TX addresses the three failure modes the Stanford study identified. Every response includes source citations linked to the specific provisions, rulings, or commentary that support the answer — not just “this document exists” but “this passage supports this claim.” Confidence scores indicate how well the retrieved sources support the generated answer, so professionals know where verification is most needed.
We don’t claim to be hallucination-free. We claim to be transparent about what we know, what we’re uncertain about, and where the professional’s own judgment is essential. That distinction matters more than any accuracy percentage.
Sources: 1. Magesh, V. et al. (2024). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies, 2025. 2. Dahl, M. et al. (2024). “Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.” Journal of Legal Analysis, 16(1), 64-93. 3. Farquhar, S. et al. (2024). “Detecting hallucinations in large language models using semantic entropy.” Nature, 630, 625-630.