Why transparency matters more than accuracy in legal AI
The AI industry obsesses over accuracy benchmarks. For tax professionals, verifiability is the metric that actually protects you.
By Auryth Team
A 95% accurate AI that never says “I’m not sure” is more dangerous than a 90% accurate one that always shows its evidence.
That sounds backward. The AI industry has spent years training us to ask one question: how accurate is your tool? Higher number, better tool, end of discussion. But if you’re a tax professional carrying professional liability for every piece of advice you give, accuracy without transparency is a trap you can’t see until it’s too late.
The wrong metric
Accuracy is a property of the system. Verifiability is a property of the output. They’re not the same thing.
When an AI tool tells you the TOB rate on accumulating ETFs is 1.32%, accuracy means the answer is correct. Verifiability means you can see that the answer traces to a specific legal provision, check the source yourself, and confirm it says what the tool claims.
An accurate answer you can’t verify is an opinion from an authority you can’t question. A verifiable answer — even one that’s occasionally wrong — is a starting point for professional judgment. You can catch the error. You can assess the reasoning. You can defend your decision.
The AI industry doesn’t measure this. Vendors publish accuracy benchmarks, not verifiability scores. That’s because accuracy is flattering and verifiability is demanding.
Why AI sounds more certain than it should
Modern AI has a design flaw that makes accuracy metrics especially misleading: it’s trained to sound confident.
Large language models undergo Reinforcement Learning from Human Feedback (RLHF), where human reviewers reward confident, well-structured answers and penalize hedging. The result: AI systems are architecturally biased toward certainty — even when the underlying evidence is thin or nonexistent.
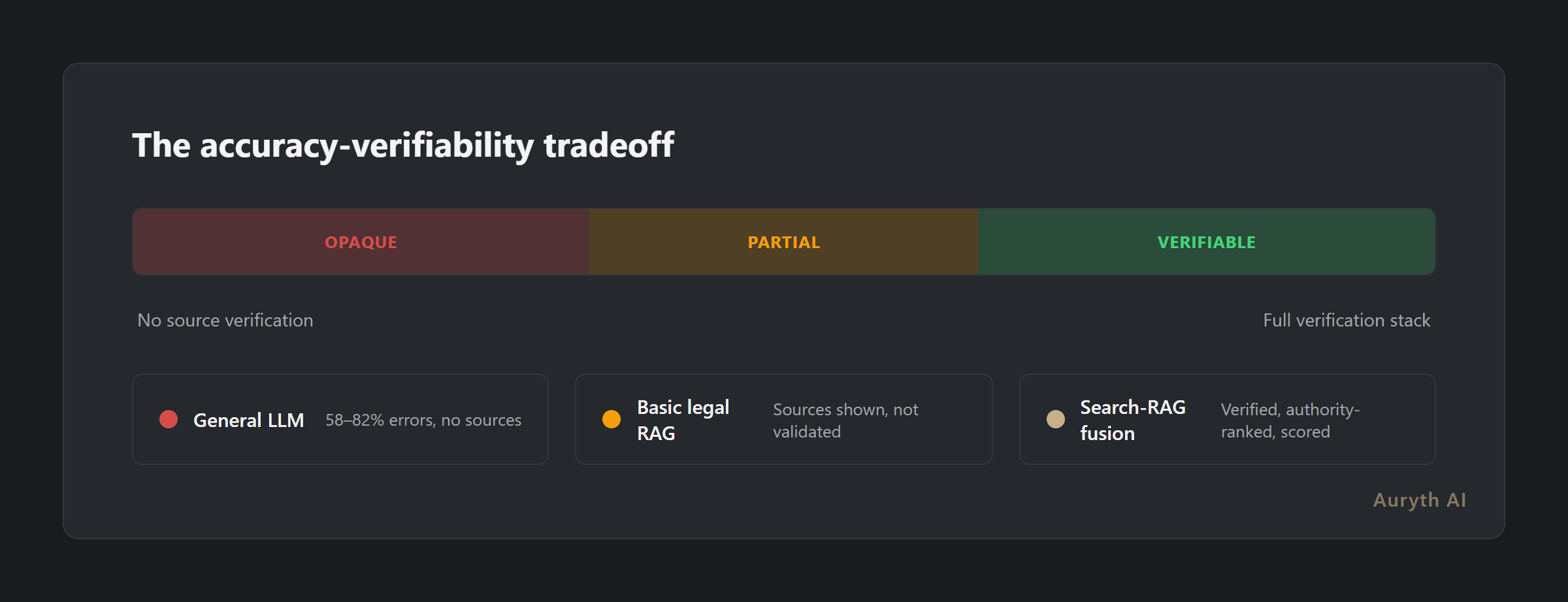
Stanford researchers found that even premium legal RAG tools hallucinate on 17–33% of queries. General-purpose LLMs fare worse: 58–88% error rates on legal questions. But the dangerous part isn’t the error rate itself — it’s that the errors don’t look different from the correct answers. A fabricated citation reads exactly like a real one. A wrong article number is stated with the same confidence as the right one.
Without source transparency, you cannot tell the 67% that’s correct from the 33% that isn’t.

What transparency actually looks like
Transparency in legal AI isn’t a marketing checkbox. It’s a set of specific engineering decisions that change how you can use the tool professionally:
| Capability | Opaque AI | Transparent AI |
|---|---|---|
| Source citations | ”Based on Belgian tax law" | "Art. 19bis WIB 92, as amended 25 December 2017” with retrievable source |
| Confidence signal | Every answer presented with equal certainty | Confidence score per claim based on source coverage and agreement |
| Thin evidence | Answers anyway, full confidence | Flags explicitly: “No specific ruling found on this point” |
| Conflicting sources | Picks one, presents as definitive | Shows both sides ranked by legal authority |
| Audit trail | Chat transcript | Structured log: query, sources retrieved, sources rejected, confidence reasoning |
| Uncertainty | Never expressed | Explicitly quantified — low confidence triggers a review warning |
The difference isn’t cosmetic. It’s the difference between a tool that replaces your judgment and one that informs it.
The verification stack: three layers of trust
Not all transparency is equal. A source citation that can’t be independently checked is theater, not transparency. Professional-grade legal AI needs three layers:
| Layer | Question it answers | What it requires |
|---|---|---|
| 1. Citation transparency | Can I see the source? | Every claim linked to a retrievable document |
| 2. Citation validation | Does the source actually say this? | Independent NLI check comparing the model’s claim against the source text |
| 3. Authority context | How strong is this source? | Legal hierarchy ranking — a Hof van Cassatie ruling outweighs a circular |
Strip any layer and the transparency claim collapses. Showing a source citation without validation is citation decoration — it looks credible without proving anything. Validating citations without authority context treats a blog post and a Supreme Court ruling as equal evidence.
The verification stack: citation transparency without validation is decoration. Validation without authority context is democracy. You need all three.
Why this matters under Belgian professional liability
Belgian tax advisors and accountants — whether registered with ITAA or operating independently — carry full professional liability for the advice they give clients. No AI tool changes this fundamental obligation. Using a tool that produced incorrect output is not a defense; relying on an unverifiable tool without independent verification could constitute insufficient due diligence.
The EU AI Act, with transparency and human oversight requirements phasing in through 2025–2026, adds a regulatory dimension. For professionals using AI in advisory work, the practical implication is straightforward: the tools you use need to support your ability to verify and oversee their output. An opaque system makes compliance harder, not easier.
A recent Thomson Reuters survey found that 59% of in-house counsel don’t even know whether their outside counsel uses generative AI. That information asymmetry — AI-assisted advice delivered without disclosure — is precisely the kind of opacity the regulatory trend aims to eliminate.
The practical question for any tax professional evaluating an AI research tool isn’t “how accurate is this?” It’s: can I verify its output quickly enough that the tool actually saves me time?
The counterargument: doesn’t accuracy matter?
Of course it does. No one wants a transparent tool that’s wrong half the time. But the debate isn’t accuracy or transparency — it’s recognizing that transparency is what makes accuracy usable.
A tool that’s 95% accurate with no verification path means you need to independently research every answer to find the 5% that’s wrong — which eliminates the time savings. A tool that’s 90% accurate but shows its sources, flags uncertainty, and ranks by authority means you can quickly confirm the 90% and focus your expertise on the 10%.
The irony: transparent tools appear less impressive because they show their uncertainty. Opaque tools look better in demos because they project confidence on every answer. But in professional practice, the tool that says “I found limited authority on this point — here are two conflicting sources, ranked by weight” is infinitely more useful than one that says “the answer is X” with no way to check.
The most dangerous AI isn’t the one that’s sometimes wrong. It’s the one that never tells you when it is.
Related articles
- What is RAG — and why it’s not enough for legal AI on its own
- AI hallucinations: why ChatGPT fabricates sources (and how to spot it)
- Confidence scoring: why it’s more honest than a confident answer
How Auryth TX applies this
Auryth TX is built on the verifiability principle — the conviction that a transparent tool is safer than an opaque one, regardless of accuracy benchmarks.
Every answer includes per-claim source citations linked to retrievable documents in the Belgian legal corpus. Every citation is independently validated: a Natural Language Inference layer checks that each source actually supports what the model attributes to it. Every source carries an authority tier — from constitutional provisions down through legislation, case law, circulars, and doctrine — so you know the weight of the evidence, not just its existence.
When evidence is thin, the confidence score drops and tells you why. When sources conflict, both sides are shown with their authority ranking. When the system searches and finds nothing relevant, it tells you — because knowing that no authority exists on a specific point is professional intelligence, not a system failure.
We publish our accuracy metrics. We show our sources. We flag our uncertainty. Not because it makes us look better — it doesn’t. But because trust without evidence is marketing, and we’re building a research tool.
See our approach to transparency — join the waitlist →
Sources: 1. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 2. Thomson Reuters Institute (2024). “ChatGPT & Generative AI within Law Firms.” 3. European Parliament (2024). “Regulation (EU) 2024/1689 — The EU AI Act.”