What is RAG — and why it's not enough for legal AI on its own
How retrieval-augmented generation works, why basic RAG still hallucinates, and what a search-RAG fusion architecture adds for tax professionals.
By Auryth Team
Every AI answer without a source citation is an opinion disguised as research. That sounds harsh — until you realize that most AI tools used by professionals today do exactly this: generate confident text from memory, with no way to check where the answer came from.
The architecture that started to fix this has a name: RAG. But basic RAG is only the beginning. Understanding what it does — and where it breaks — is the most important thing a tax professional can learn about AI in 2026.
What is retrieval-augmented generation?
Retrieval-Augmented Generation (RAG) is an AI architecture where the system first searches a knowledge base for relevant documents, then sends those documents — along with your question — to a language model that formulates an answer based on what it found. Unlike chatbots that answer from memory, a RAG system bases every response on retrievable sources.
Think of the difference between two colleagues. One answers your tax question from memory — confidently, sometimes correctly, sometimes not. The other walks to the library, pulls the relevant provisions, reads them, and then gives you an answer with page numbers. RAG is the second colleague.
The concept was formalized by Lewis et al. in a 2020 paper at NeurIPS, combining parametric memory (the language model’s trained knowledge) with non-parametric memory (a searchable document index). The insight was simple but transformative: instead of forcing a model to memorize everything, let it look things up.
Why basic RAG isn’t enough
Here’s what most RAG explainers don’t tell you: vanilla RAG — dump documents into a vector database, connect a language model, done — still hallucinates on 17–33% of legal queries. Stanford researchers proved this by testing Westlaw AI and Lexis+ AI, both RAG-based systems built by the largest legal publishers in the world.
Why? Because legal text isn’t like Wikipedia articles. It has structure that basic RAG ignores:
Hierarchy. A Hof van Cassatie ruling outweighs a Fisconetplus circular. Basic RAG treats them as equal chunks of text. When a circular contradicts case law, a system with no authority awareness picks whichever text matches your query best — which might be the wrong one.
Temporality. The Belgian corporate tax rate was 29.58% in 2019 and 25% today. Basic RAG retrieves whichever version its vector search surfaces first. Ask about 2019 and you might get 2026’s rate — stated with full confidence.
Cross-references. A single tax question can span Art. 19bis WIB, the TOB framework, and a Vlaamse Codex Fiscaliteit provision simultaneously. Basic RAG retrieves fragments. It doesn’t understand that these provisions interact.
The generation step compounds the problem. Even with correct retrieval, the language model can misinterpret, over-generalize, or combine sources in ways the original texts don’t support. Citation validation — checking that each claimed source actually says what the model attributes to it — is a necessary additional layer that basic RAG doesn’t include.
Dumping documents into a vector database is the minimum viable RAG. For legal work, it’s the maximum viable liability.
From basic RAG to search-RAG fusion
The insight that separates professional-grade legal AI from a demo is this: RAG is a generation strategy, not a search strategy. The “retrieval” in RAG is only as good as the search infrastructure underneath it.
A search-RAG fusion architecture layers professional search capabilities before the language model ever sees a document:

| Step | What happens | Why basic RAG can’t do this |
|---|---|---|
| 1. Parse | The system identifies the tax domain, jurisdiction, and time period from your question | Basic RAG just embeds the raw question — no domain awareness |
| 2. Hybrid search | Two search strategies run in parallel: BM25 (exact legal terms like “Art. 344 WIB”) and vector embeddings (semantic meaning). Results are merged via Reciprocal Rank Fusion | Basic RAG uses only vector search — misses exact article references |
| 3. Authority ranking | Results are reranked by legal weight: Constitution → EU law → federal statutes → case law → circulars → doctrine | Basic RAG treats all documents equally |
| 4. Cross-encoder reranking | A specialized model reads each source alongside your question and scores true relevance | Basic RAG relies on embedding similarity, which misses nuance |
| 5. Generate + cite | The language model reads the ranked sources and produces a structured answer — every claim linked to its source | Same as basic RAG, but with far better inputs |
The difference between step 2 alone (basic RAG) and steps 1–4 working together (search-RAG fusion) is the difference between finding some relevant text and finding the right law, from the right authority, at the right point in time.
Why verifiability matters more than accuracy
Most RAG explainers focus on accuracy — RAG reduces hallucinations, RAG gives better answers. That’s true, but it misses the point.
The real advantage isn’t accuracy. It’s verifiability.
A fine-tuned model might be 95% accurate. A search-RAG system might be 92% accurate. But the search-RAG system shows you exactly which sources it used, ranked by legal authority, so you can check the 8% yourself. The fine-tuned model gives you no way to know which answers fall in the 5%.
For a tax professional, this difference is everything. Your professional liability doesn’t depend on the tool’s accuracy. It depends on whether you verified the advice you gave your client.
The question isn’t “is this AI accurate?” The question is “can I check?”
We call this the verifiability principle: a tool that is 90% accurate and transparent is safer than one that is 95% accurate and opaque. Every percentage point of accuracy you can’t verify is a liability you can’t manage.
Search-RAG fusion vs. fine-tuning: the library vs. the textbook
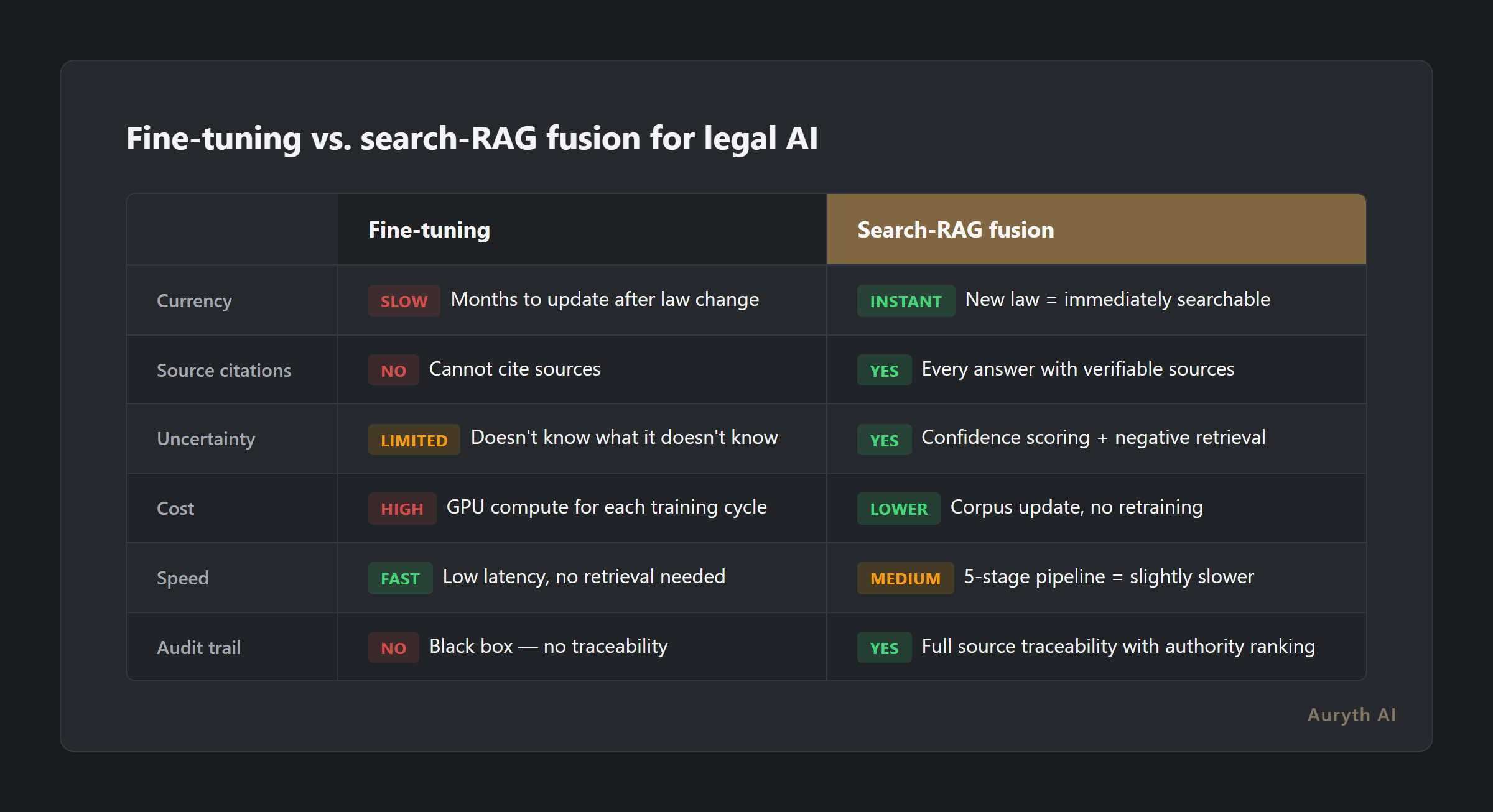
The main alternative to RAG-based approaches is fine-tuning — training a model on domain-specific data so the knowledge gets baked into its weights. Think memorizing a textbook versus having access to a library with a professional librarian.
| Aspect | Fine-tuning | Search-RAG fusion |
|---|---|---|
| Knowledge source | Baked into model weights | Retrieved from curated, structured corpus |
| Updatability | Retrain the model (weeks, expensive) | Update the corpus (hours, cheap) |
| Transparency | Black box — can’t trace answers to sources | Full citation chain with authority ranking |
| Belgian tax suitability | Law changes faster than models retrain | New provision = immediately searchable with metadata |
| Cost | High (GPU compute for training) | Lower (search infrastructure) |
| Hallucination risk | Hallucinates confidently, no way to check | Can still hallucinate, but every source is verifiable |
Harvey, backed by over a billion dollars in funding, initially chose fine-tuning for its US-focused legal AI. That makes sense for a relatively stable legal system with deep pockets for continuous retraining. Belgian tax law — with three regions, two official languages, constant legislative amendments, and a regulatory landscape that shifts quarterly — demands a different approach.
When the Flemish inheritance tax brackets change, a fine-tuned model needs retraining. A search-RAG system needs a corpus update.
What this looks like in Belgian tax practice
Consider a question any Belgian tax professional might face: “What are the TOB implications of switching from a distributing to an accumulating ETF?”
A general-purpose LLM will answer from training data — which may be months or years out of date, may confuse Belgian and Dutch rules, and cannot cite the specific article in WIB 92 or the relevant Fisconetplus circular.
A search-RAG fusion system built for Belgian tax does this:
- Parses the question — identifies TOB as the tax domain, determines the relevant assessment period, flags that fund classification matters
- Searches the Belgian legal corpus using hybrid search — BM25 catches “TOB” and specific article numbers exactly, vector search catches semantically related provisions about fund taxation
- Ranks by authority — a legislative provision outweighs a circular; a Hof van Cassatie ruling outweighs doctrine
- Reranks by relevance — a cross-encoder model scores each candidate against your actual question, filtering false positives
- Generates a structured answer citing each source, with a confidence score per claim
- Flags gaps — if no specific ruling exists on a nuance of your question, it tells you
That last point matters as much as the answer itself. In professional tax practice, knowing that no authority exists on a specific point is valuable intelligence — it means you’re in interpretation territory and should proceed accordingly.
The honest limitations
Even a well-architected search-RAG fusion system has real limits:
Retrieval quality is the ceiling. If the right document isn’t in the corpus, or the search pipeline doesn’t surface it, the model can’t use it. The system is only as good as its knowledge base and its search algorithms.
The generation step can still fabricate. Even with perfect retrieval and ranking, the language model can misinterpret sources or combine them in ways the originals don’t support. That’s why citation validation — independently checking that each cited source says what the model claims — is a necessary post-generation layer.
Complexity has a cost. A five-stage pipeline is slower than a single vector lookup. The tradeoff is worth it for professional work where correctness matters more than speed — but it’s a tradeoff nonetheless.
The honest assessment: search-RAG fusion reduces the problem from catastrophic (58–88% hallucination in general LLMs) to manageable (significantly below the 17–33% of basic legal RAG, with additional verification layers). But “manageable” still means professional judgment remains essential. The system accelerates your research — it doesn’t replace your expertise.
Related articles
- AI hallucinations: why ChatGPT fabricates sources (and how to spot it)
- I asked ChatGPT and Auryth the same Belgian tax questions — here’s what happened
- Fine-tuning vs. RAG: two ways to make AI smart
How Auryth TX applies this
Auryth TX doesn’t use basic RAG. It fuses professional search infrastructure with retrieval-augmented generation — because the quality of the retrieval determines the quality of the answer.
Every question runs through a five-stage pipeline: hybrid search (BM25 + vector embeddings merged via Reciprocal Rank Fusion), authority ranking across a 13-tier Belgian legal hierarchy, cross-encoder reranking for precision, structured answer generation with per-claim citations, and post-generation citation validation with confidence scoring.
The Belgian legal corpus is our knowledge base: WIB 92, Fisconetplus, DVB advance rulings, VCF, court decisions, and doctrinal publications — all structured with temporal metadata, jurisdiction tags, and authority tiers. When sources conflict, both sides are shown. When evidence is thin, the confidence score tells you explicitly. When the law changes, the corpus updates within hours.
We don’t ask you to trust the AI. We ask you to check the sources it shows you. That’s the verifiability principle in practice.
See how our search-RAG pipeline works — join the waitlist →
Sources: 1. Lewis, P. et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS. 2. Magesh, V. et al. (2025). “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools.” Journal of Empirical Legal Studies. 3. Schwarcz, D. et al. (2025). “AI-Powered Lawyering: AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice.” SSRN.